A raspagem da Web é um dos métodos mais comuns de coleta de dados, mas sua legalidade ainda é um tópico muito debatido. Então, a raspagem da Web é legal? Embora a resposta não seja tão simples, nesta postagem vamos dar uma olhada no que é raspagem da Web, suas implicações legais e práticas recomendadas. Vamos nos aprofundar no assunto!

O que é raspagem da Web?
Web scraping (ou raspagem de dados): o que é e como funciona
O Web scraping envolve a extração de dados de um site. As informações coletadas são exportadas em um formato mais útil para o usuário.
Em termos mais técnicos, o scraper usa o código/elementos HTML, CSS ou JavaScript de uma página da Web e extrai todos os dados presentes ou seleciona algumas informações específicas de valor. Na verdade, a raspagem da Web permite que você direcione informações específicas (por exemplo, raspar uma página da Amazon para obter preços, mas não para obter avaliações de produtos).
Em geral, a raspagem da Web é feita por meio de ferramentas dedicadas e automatizadas que funcionam mais rapidamente do que a raspagem manual.
Exemplos de raspagem da Web
Embora a raspagem da Web envolva desenvolvedores, pois pode ser bastante técnica, ela é uma ferramenta valiosa para pesquisadores, jornalistas, acadêmicos e outros.
A raspagem da Web pode ser usada para:
- Pesquisa de mercado (ou seja, análise da concorrência em dados de produtos de sites de comércio eletrônico, como Amazon ou eBay);
- Monitoramento de preços (ou seja, preços de ações);
- Monitoramento de notícias;
- Reunir localizadores de lojas, estatísticas esportivas, etc.
A raspagem da Web é legal?
A legalidade da raspagem da Web
Assim como a maioria das pessoas que pesquisam esse tópico, você deve estar se perguntando: a raspagem de dados é legal? Não fique muito entusiasmado, pois, infelizmente, todo o assunto continua sendo uma área cinzenta.
A raspagem da Web geralmente é permitida quando:
- os dados extraídos são dados disponíveis publicamente; e
- as informações coletadas não são protegidas por um login.
Em geral, a raspagem responsável da Web exige que você seja cauteloso em relação aos Termos de Serviço aplicáveis, aos dados protegidos por direitos autorais e aos dados pessoais (já que os dados pessoais são normalmente protegidos por leis de privacidade).
Dê uma olhada em nosso guia detalhado sobre o que é considerado informação pessoal nas principais leis de privacidade.
Extração de dados de acordo com as leis de privacidade
As principais leis de privacidade até o momento na UE ( GDPR) ou nos EUA ( CPRA) visam proteger os dados pessoais do usuário e definir uma estrutura para o uso desses dados.
Eles não se referem à raspagem da Web nem declaram que ela é ilegal. No entanto, eles regulam a coleta de dados pessoais pelas empresas e o que elas podem fazer com esses dados. Em resumo – porque sim, a lei é muito mais complicada do que isso! – ela geralmente envolve:
- receber o consentimento explícito dos titulares dos dados;
- coletar dados pessoais somente para fins específicos;
- informar aos usuários quais dados são coletados, como e quais são seus direitos.
Em resumo, se as suas atividades de raspagem da Web envolverem a raspagem de informações pessoais, você deverá certificar-se de que está em conformidade com as leis de privacidade de dados.
Não tem certeza de quais leis de privacidade realmente se aplicam a você?
Orientação garantida
Observe que, embora essa orientação venha da Garante italiana, as sugestões são úteis para todos os países.
Em maio de 2024, a Garante publicou um documento de orientação que contém instruções para a defesa de dados pessoais publicados on-line por entidades públicas e privadas como controladores de dados contra a raspagem da Web no contexto do treinamento de IA generativa. O Garante sugere uma série de medidas concretas a serem adotadas, incluindo
- a criação de áreas reservadas, acessíveis somente mediante registro, de modo a remover os dados da disponibilidade pública;
- a inclusão de cláusulas anti-scraping nos termos de serviço de sites ou plataformas on-line;
- o monitoramento do tráfego para páginas da Web, de modo a identificar quaisquer fluxos anormais de dados de entrada e saída (um exemplo de medida adequada a ser tomada é limitar o tráfego de rede e o número de solicitações de acesso, selecionando apenas aquelas provenientes de determinados endereços IP); e
- a implementação de medidas específicas contra bots usando algumas soluções tecnológicas (por exemplo: intervir no arquivo robots.txt; incluir verificações CAPTCHA; fazer modificações periódicas na marcação HTML; incorporar conteúdo ou dados destinados a evitar atividades de raspagem em itens multimídia, como imagens).
Por meio da adoção dessas ações, embora elas não sejam exaustivas em termos de método ou resultado, os operadores de sites e plataformas on-line podem conter os efeitos da raspagem destinada a treinar algoritmos de inteligência artificial generativa.
Decisões anteriores e casos comuns
Alguns casos dignos de nota em que a raspagem da Web é ilegal e dos quais você deve estar ciente incluem indivíduos ou empresas que abusam da raspagem da Web e violam os Termos de Serviço ou as normas de direitos autorais.
📌 Decisão do Tribunal de Apelações do Nono Circuito dos EUA – LinkedIn vs. HiQ
O LinkedIn entrou com uma ação para impedir que um concorrente, a HiQ, extraísse informações pessoais dos perfis públicos dos usuários do LinkedIn.
Em 2020, a decisão estabeleceu que a CFAA não foi violada, pois os dados extraídos do LinkedIn eram públicos (não estavam protegidos por uma senha).
Clearview AI Fine
A empresa de reconhecimento facial recebeu uma multa pesada por extrair milhões de fotos de rostos de pessoas das mídias sociais.
Foi declarado que a Clearview AI estava processando dados confidenciais sem uma base legal válida. Leia a história completa em nosso blog.
O que você precisa fazer
Como um raspador da Web
Tenha cuidado ao fazer download de dados de um site que exija que você faça login, pois isso pode significar que você concordou com os Termos de Serviço, que podem proibir atividades de raspagem da Web.
Certifique-se de verificar os Termos e Condições do site para garantir que você não esteja violando o contrato.
Mesmo que sejam dados disponíveis publicamente, verifique se os dados não estão protegidos por direitos autorais. Isso pode incluir artigos, vídeos e designs.
Por fim, e mais importante, considere a ética envolvida. Mesmo que uma atividade não seja ilegal, ela ainda pode causar danos ou prejuízos à reputação de você ou de outras pessoas.
Como proprietário de um site
Para proteger seu site contra a extração de informações, você pode:
Proteja seu site com direitos autorais e escreva uma cláusula de direitos autorais;
Você deve adicionar restrições de raspagem da Web ao documento de Termos e Condições do seu site. Ao fazer isso, certifique-se de que a linguagem seja específica e proíba terceiros de coletar informações e usá-las para fins comerciais, por exemplo.
👋 Veja como você pode fazer isso facilmente com as soluções de software da iubenda:
🚀 Use o Gerador de Termos e Condições da iubenda;
🚀 Crie um documento de termos e condições personalizado para você;
Crieuma cláusula personalizada ou selecione nossas cláusulas pré-elaboradas, incluindo cláusulas de direitos de conteúdo;
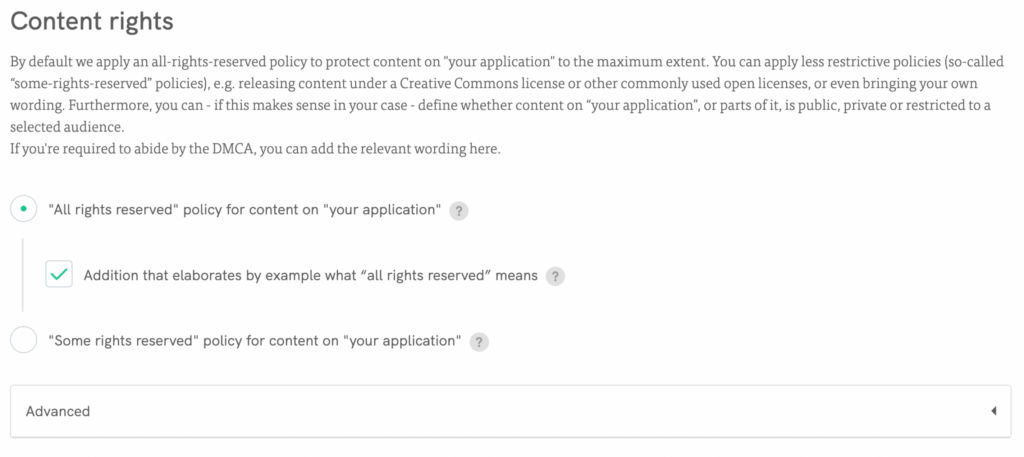
Adicione facilmente uma cláusula antirraspagem: Uso aceitável → Cláusula de uso aceitável personalizada (lista com declarações específicas para usos aceitáveis/proibidos, aprofundando-se com exemplos e declarações) → Adicionar uma lista com restrições de raspagem
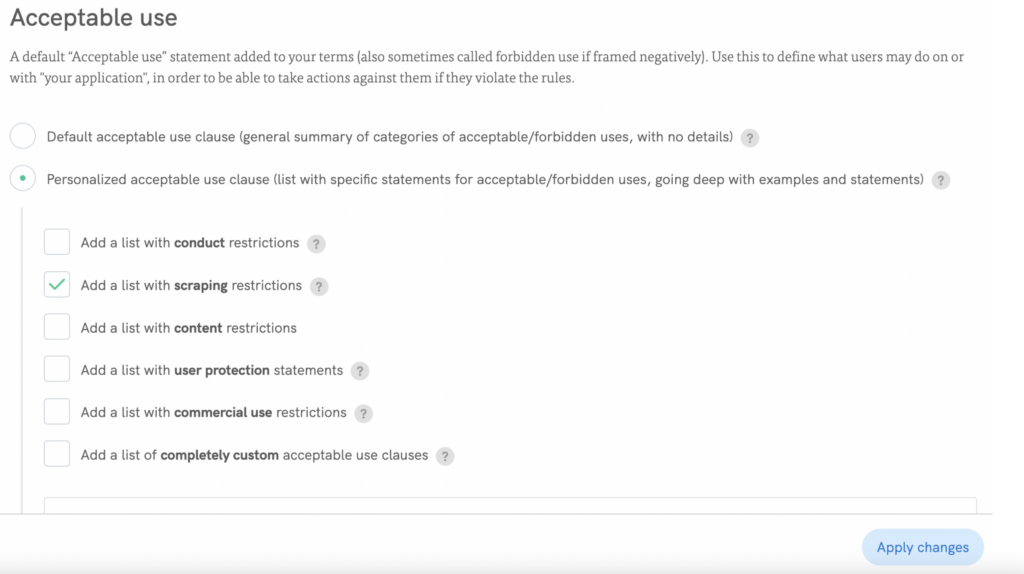
Siga nossas instruções para instalar rapidamente o documento em seu site!
About us

Attorney-level solutions to make your websites and apps compliant with the law across multiple countries and legislations.